Introducing Superlinear: Subquadratic Attention for Million-Token Contexts
TL;DR
- Attention's quadratic cost is the fundamental bottleneck for long-context inference.
- We propose Superlinear Multi-Step Attention: a fully trainable attention architecture that achieves O(L^{3/2}) complexity while preserving the ability to attend to any token in the context — no hard-coded exclusions.
- We built an inference engine on top of it with stateful sessions, KV cache management, and an OpenAI-compatible API.
- On a single B200 GPU, we achieve 109 tokens/sec at 1M tokens and 76 tokens/sec at 10M tokens of context.
- The model weights and inference engine are open-sourced. This is an early research release.
1) The problem: attention doesn't scale
Long context is one of the most important frontiers in language model research. The ability to hold an entire codebase, a book, or a legal corpus in a single model pass — without chunking, summarizing, or retrieving — changes what AI systems can actually do. Retrieval-augmented architectures have been the workaround for years, but they come with a fundamental limitation: the model can only reason over what ends up in its context window, and retrieval is an imperfect filter.
The bottleneck isn't model quality. It's the attention mechanism itself.
Standard causal self-attention scales as O(L²) with sequence length. At 128K tokens, that's roughly 16 billion attention operations per layer. At 1M tokens, it's 10,000× more. Dense attention at these scales requires either enormous compute, prohibitive latency, or hardware that only a handful of organizations can access.
Existing approaches to reduce this cost tend to make one of two tradeoffs:
- Linear attention / SSMs (RNNs): O(L) complexity, but they compress the context into a fixed-size recurrent state. Any token that "falls off" the state is structurally unreachable for future queries. This is fast but lossy.
- Sparse or block retrieval attention: These methods achieve sub-quadratic attention by restricting which tokens can attend to which others — either through fixed sparsity patterns (sliding windows, dilated attention) or learned retrieval over blocks. The retrieval step itself can still be O(L²), and many approaches hard-code exclusions that prevent certain tokens from ever being attended to.
The ideal would combine the efficiency of subquadratic methods with the completeness guarantee of dense attention: any token in the context can be reached if the model learns it's relevant. We call this property random context access — or more precisely, structural non-exclusion: no eligible token position is permanently ruled out by the architecture.
2) The insight: attention as search
The core idea in Superlinear attention comes from an analogy with classical search algorithms.
In jump search on a sorted array, you don't scan every element linearly, and you don't do full binary search. Instead, you search over √L "anchor" positions to identify a relevant block, then search within that block. This achieves O(√L) search complexity while still reaching any element.
We applied this structure to attention: instead of attending to all L positions at once (O(L²) total) or attending to an arbitrary fixed subset (which breaks completeness), we route attention through a learned two-step process:
- Span search: Score O(√L) candidate anchor positions using an efficient search query, select the top-k.
- Span attention: Attend to contiguous spans of O(√L) tokens centered at each selected anchor.
The family of candidate spans — one per anchor, plus a local sliding window for recent tokens — collectively covers every eligible key position. The router selects a small subset to actually attend to, but nothing is structurally unreachable. This is what "random context access" means in concrete terms.
The total complexity is O(L^{3/2}) for both span search and span attention — the two-step balanced setting where neither dominates. This generalizes: with N steps, the complexity is O(L^{1+1/N}), approaching O(L log L) as N grows.
Critically, the routing mechanism is fully differentiable and learned end-to-end. The model learns to send attention where it matters, rather than following any fixed pattern.
3) Architecture: four components
Superlinear attention consists of four components that work together:
Input tokens
↓
Accumulation (Mamba-2 linear recurrence — O(L), builds prefix summaries)
↓
Span Search (O(L^{3/2}) — scores O(√L) anchors per query, selects top-k)
↓
Span Attention (O(L^{3/2}) — attends over contiguous spans at selected anchors)
↓
Combination (O(L) — softmax-weighted gating over span outputs, differentiable)
↓
Output
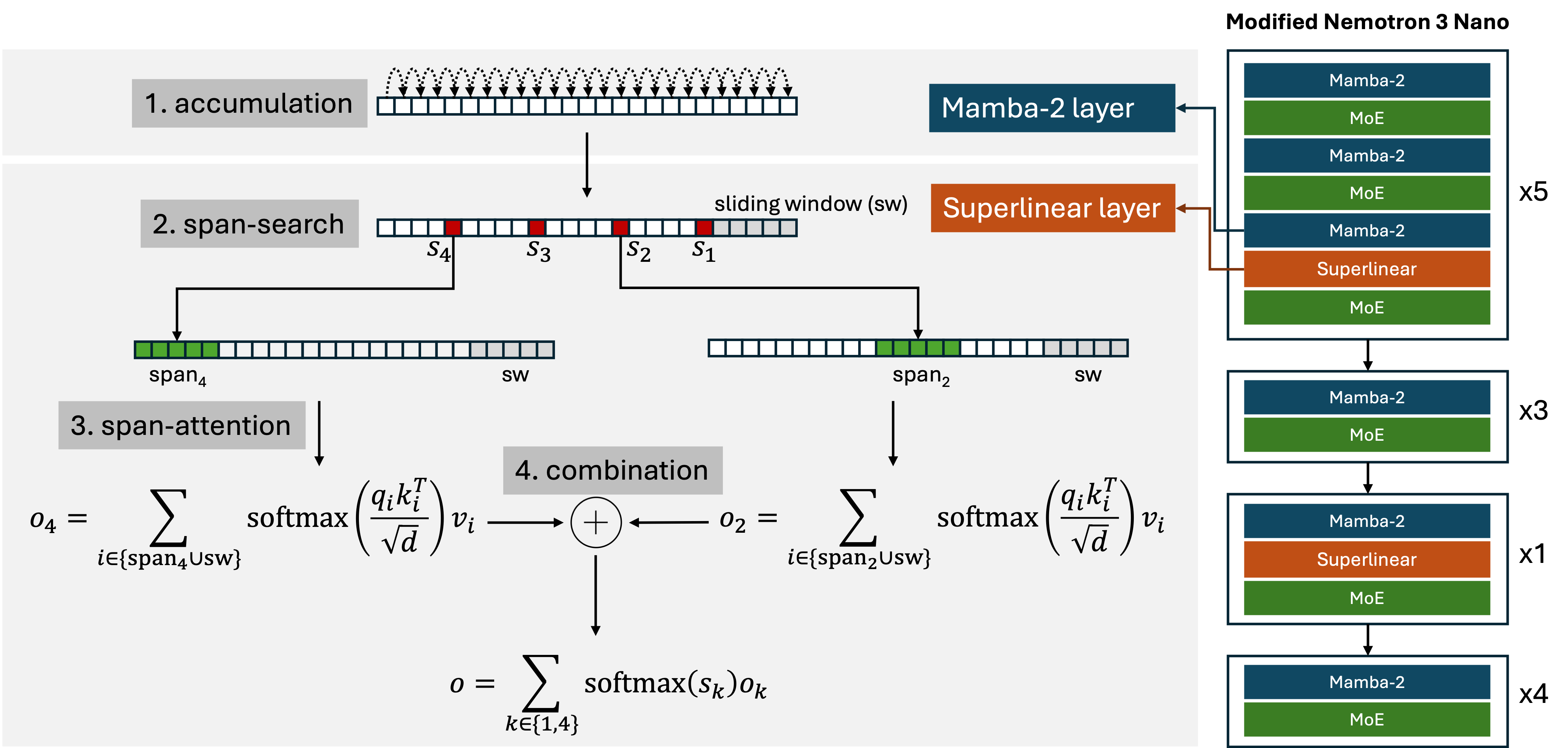
Accumulation uses a linear recurrence (Mamba-2) to build a compact prefix summary for each position. This summary is reused as the key signal for span search — no separate encoding pass is needed.
Span search scores a sublinear set of candidate anchors using a learned search query against the accumulated keys. The anchor stride pattern is deterministic (power-law spacing), but the selection of which anchors to attend to is content-dependent.
Span attention is standard attention restricted to the selected spans. Because spans are contiguous in memory, this is efficient to implement.
Combination merges the outputs of the top-k spans using softmax-weighted gating over the span search scores. This is the mechanism that makes routing differentiable — gradients flow back through the gating weights into the search scores and ultimately into Q_s, letting the router be trained end-to-end.
We implement this by replacing the standard attention layers in NVIDIA Nemotron-3-Nano-30B-A3B (a 30B hybrid MoE model) with Superlinear attention layers. The Mamba-2 layers already present in the base architecture serve naturally as the accumulation step, and we add only a search query projection Q_s to each layer. The KV cache interface is unchanged.
4) Making it fast: bucketed kernels
The theoretical O(L^{3/2}) advantage doesn't translate to practice unless the GPU implementation handles the irregular span pattern efficiently. Span attention has a different footprint for each query — each query attends to a different span window depending on which anchor was selected. This kind of content-dependent irregularity is exactly what standard tiled attention kernels aren't designed for.
We solve this with a bucketed kernel design: instead of sorting queries globally (which adds O(L log L) overhead and requires permuting tensors), we group queries by the "key-block footprint" of their selected span — which block range of the key sequence they need to access. Queries in the same bucket share the same memory access pattern and can be processed together in a single kernel tile, achieving efficient GPU tiling without global sorts.
The bucketed approach uses dynamic work-stealing and atomic counters to handle variable bucket sizes while maintaining high GPU occupancy. At prefill time, this lets us process all L queries efficiently despite the irregular pattern.
At decode time, the problem is simpler: each step evaluates a single query, so there's no cross-query irregularity. The decoder computes routing scores over the anchor set for the current position and runs attention over the resulting spans using standard primitives.
5) Throughput results
All measurements on a single NVIDIA B200 GPU (180 GB VRAM), batch size 1, chunked prefill with 32K chunks.
Prefill comparison vs. FlashAttention-2:
FlashAttention-2 is faster at short contexts (< ~60K tokens), where dense attention is well-optimized. Superlinear attention overtakes it near 60K tokens and scales into the multi-million-token regime where dense attention becomes impractical:
| Context Length | Prefill (tok/s) | Decode (tok/s) | Decode Latency |
|---|---|---|---|
| 1M tokens | ~20,000 | ~109 | ~9.2 ms/tok |
| 10M tokens | ~5,500 | ~76 | ~13.2 ms/tok |
At 10M context, prefill takes roughly 30 minutes. Decode latency at 76 tokens/sec keeps generation interactive even at 10M tokens — which is approximately the equivalent of 30 full novels, or a large enterprise codebase, held in a single context.
For comparison, at 10M tokens, FlashAttention-2 decode throughput has dropped to near-zero — the O(L²) prefill becomes infeasible and the O(L) per-token decode cost is prohibitive.
A note on memory: model weights for concavity-ai/superlinear-exp-v0.1 require ~60 GB VRAM at 16-bit precision. KV cache adds ~6 GB per 1M tokens of active context. A single A100 (80 GB) can run up to ~2M context; a B200 (180 GB) supports 10M+.
6) Training: NIAH retrieval validation
With limited fine-tuning on a synthetic long-context retrieval task (Needle in a Haystack / NIAH from the RULER benchmark), the routing mechanism is learnable end-to-end. We use curriculum learning — starting at 4K context and increasing to 64K over the course of training.
The result is strong retrieval accuracy across context lengths from 4K to 256K tokens and across needle depth positions (from the very beginning to the very end of the context). Performance improves with additional routing redundancy (more candidate spans per query), and the architecture generalizes to longer contexts than those seen during training.
This is a feasibility result, not a comprehensive evaluation. The trained model hasn't been evaluated on diverse generative tasks, instruction following, or reasoning benchmarks. We're publishing the architecture and initial evidence now, with broader evaluation to follow.
7) The inference engine: stateful, session-based
We built an inference engine around the model that exposes the key differentiators of long-context inference that stateless API wrappers miss.
Stateful sessions: instead of re-prefilling the entire conversation each turn (the typical stateless API model), Superlinear keeps the KV cache alive across turns. For a 1M-token context, re-prefilling every turn would be prohibitively slow. Sessions make multi-turn interaction at long context actually usable.
Snapshots: save the full session state (KV cache + history) to disk, restore it later without re-processing. Document ingestion is expensive once; with snapshots you do it once and fork from there.
OpenAI-compatible API: any OpenAI SDK client works out of the box. Sessions and snapshots are exposed as additional API extensions, not as replacements for the standard chat completions interface.
CLI (spl): a command-line interface for chat, document Q&A, session management, and server control. Document workspaces support multi-document ingestion, BM25 retrieval, and snapshot-based warm starts.
The server is designed for a realistic single-user or small-team deployment pattern: a long-context model running locally or on private infrastructure, with stable, controllable sessions.
8) What this is (and isn't)
What it is:
- A new attention architecture with provably subquadratic complexity and random context access
- A practical implementation that runs efficiently at 10M+ tokens on a single GPU
- An inference engine with stateful sessions, snapshots, and OpenAI-compatible API
- Model weights released as an experimental research artifact:
concavity-ai/superlinear-exp-v0.1
What it isn't (yet):
- A comprehensive benchmark comparison against frontier models
- A production-ready system (research preview, limited safety and quality evaluation)
- A general-purpose chat model optimized for instruction following across all tasks
The released model (superlinear-exp-v0.1) is a fine-tuned checkpoint of Nemotron-3-Nano-30B-A3B evaluated primarily on NIAH retrieval. It supports thinking mode, document Q&A, and multi-turn sessions — but it hasn't been extensively tested beyond that. We're releasing it now to let researchers and builders experiment, report findings, and help us understand where the architecture succeeds and where it needs work.
9) What's next
The throughput results at 10M+ context are the starting point, not the end goal.
We're using the Superlinear model as the foundation for more demanding reasoning workloads — where the question isn't just "can we hold a large context" but "can we reliably reason across it." Multi-document reasoning tasks require not just long contexts but structured, verifiable reasoning over those contexts.
Get started
# Install
git clone https://github.com/concavity-ai/superlinear.git
cd superlinear
conda env create -f environment.yml
# (see docs/installation.md for full setup)
# Start server
spl server start --model concavity-ai/superlinear-exp-v0.1
# Chat
spl chat
# Document Q&A
spl docs my-corpus
The paper is on arXiv: Superlinear Multi-Step Attention.
Model weights: concavity-ai/superlinear-exp-v0.1 on HuggingFace.