RAG-Extended FCR Outperforms RAG and Multi-Agent Systems on a Legal Retrieval Benchmark
TL;DR
- FCR was already strong at document-level reasoning inside a 1M-token context window. We further scale FCR to unlimited corpus by extending it with RAG.
- On the LegalBench-RAG benchmark, RAG-extended FCR outperforms both classic RAG and advanced multi-agent systems (MAS) such as PAKTON, scoring about 8x higher F1 than the LegalBench-RAG baseline and roughly 38% higher F1 than PAKTON.
- FCR reaches 99% document-level recall, making it nearly perfect at surfacing the right governing documents for downstream reasoning.
1) Scaling FCR Beyond the Context Window
FCR was introduced to reason and verify over full documents because legal reasoning breaks down when systems operate over isolated fragments. A snippet can look responsive while omitting the definition that controls it, the exception that narrows it, or the neighboring provision that reverses its practical effect. For serious legal and enterprise work, the task is not to retrieve a plausible passage and stop there. It is to reason correctly over the documents that control the answer. That requires verified, document-level analysis.
FCR is already strong inside a 1M-token context window. It can reason directly across hundreds of documents in a single pass. But 1M tokens is still a fixed budget. Once the corpus grows beyond that limit, FCR needs a way to scale without giving up the reasoning strengths that make it valuable in the first place.
That is why we extend FCR with RAG. The goal is to preserve FCR's strong document-level reasoning while removing the practical limit on how many candidate documents the system can handle. Retrieval surfaces the documents that matter from a much larger archive, and a final FCR pass over those retrieved documents produces the result.
With this extension, FCR is no longer restricted to the documents that fit inside a fixed context window. It can now reason over effectively unlimited document sets while preserving the capabilities that make it work inside long context.
2) The Results: RAG vs Multi-Agents vs FCR
On LegalBench-RAG, the RAG extension of FCR outperforms both classic RAG and advanced multi-agent systems such as PAKTON.
| System | Precision | Recall | F1 |
|---|---|---|---|
LegalBench-RAG @ best k=2 (Classic RAG) | 5.29% | 11.33% | 7.21% |
PAKTON @ best k=2 (Multi-Agent System) | 30.34% | 67.47% | 41.86% |
| FCR | 49.87% | 86.15% | 57.73% |
| FCR (Document Retrieval) | 89.00% | 99.00% | 91.00% |
The F1 performance of classic RAG is only single-digit. PAKTON improves on that baseline substantially and reaches 41.9% F1. FCR still clears it by a wide margin, reaching 57.7% F1 with 86.2% recall. That means FCR scores about 8x higher F1 than the classic RAG baseline and roughly 38% higher F1 than PAKTON.
The precision and recall breakdown makes the result even more revealing. Classic RAG is weak on both dimensions. It misses most of the relevant evidence and is rarely precise when it does retrieve something. PAKTON improves the picture substantially, especially on recall, showing that a serious multi-agent system can recover much more of the benchmark evidence. But FCR still establishes a clear lead over both systems. Its precision rises to 49.87%, compared with 30.34% for PAKTON and 5.29% for classic RAG, while its recall reaches 86.15%, versus 67.47% and 11.33% respectively. This is not a narrow tradeoff. FCR finds more of the right evidence while making materially fewer mistakes.
The more important result is the document-level one. FCR reaches 99% recall with 89% precision at the document retrieval surface. That means it is nearly perfect at surfacing the right governing documents before the final FCR pass. In a legal setting, that is the number that matters most. If the right documents are missing, downstream reasoning has no chance. FCR gets those documents into view with near-perfect coverage.
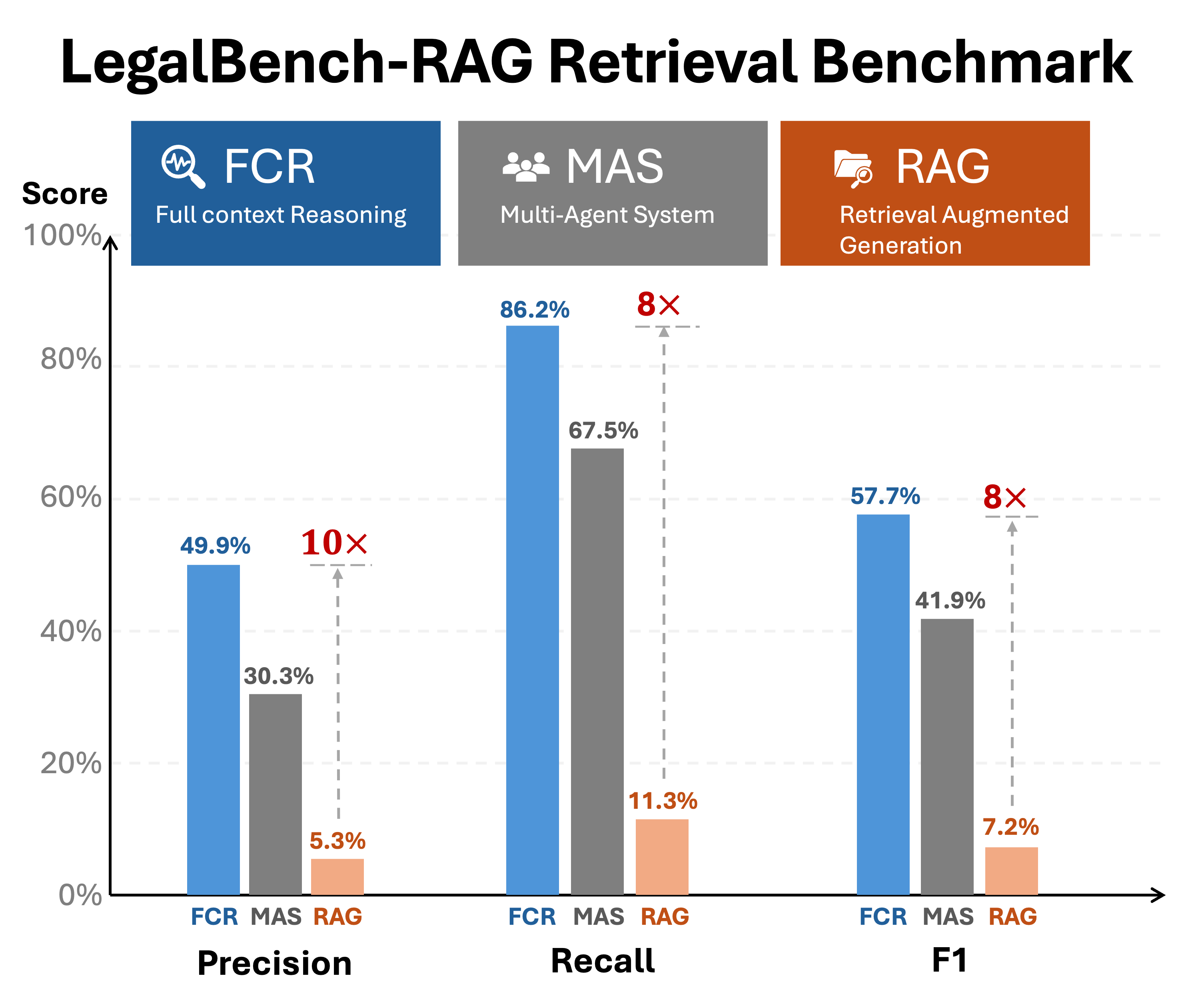
Figure 1: LegalBench-RAG benchmark comparison across precision, recall, and F1. FCR leads both classic RAG and the multi-agent PAKTON baseline.
3) The Benchmark and the Multi-Agent Baseline
LegalBench-RAG is a legal retrieval benchmark built for exactly this problem. The benchmark spans more than 79 million characters of legal source text, far beyond what fits in any single model context window. That is the kind of scale where retrieval quality determines whether downstream reasoning has any chance of being correct. In this evaluation, we use its ContractNLI slice.
PAKTON is the best performing system on this benchmark. It is a three-agent system with Archivist, Researcher, and Interrogator roles, built specifically to refine retrieval across multiple reasoning steps. That is what makes this result meaningful. FCR is not beating a weak baseline. It is beating a serious multi-agent system designed for exactly this class of problem.
4) Why RAG Alone Is Not Enough
RAG and long-context reasoning are often framed as competing paradigms. For serious enterprise and legal work, that framing is wrong.
When the candidate documents fit inside the model's context window, full-context document-level reasoning is the stronger approach. But when the corpus scales into thousands of documents, some filtering step becomes necessary.
The mistake is letting that filtering step fracture the reasoning process itself. The right approach is to use RAG to surface the right documents, then reason over them at the document level. That is exactly what the RAG extension of FCR does.
This matters beyond a single benchmark. System design has been moving in a clear direction. First came classic RAG. Then agentic RAG. Then multi-agent systems built to recover more evidence and coordinate more reasoning steps. Each generation was an attempt to compensate for the same underlying weakness. Retrieval alone was not enough.
RAG-extended FCR is the next step in that progression. It keeps the scale benefits of retrieval, but restores document-level reasoning where the final answer is actually produced. That is why we see it as multiple generations ahead of classic RAG. The industry kept adding orchestration on top of fragmented evidence. We move past that by combining scalable retrieval with full-context reasoning over the documents that actually govern the answer.
That is also the same pattern we have seen in our earlier results. Across our previous research posts, FCR consistently outperformed RAG-based systems, whether the alternative was plain RAG or more elaborate agentic RAG. What is notable here is that the pattern still holds even after extending FCR with retrieval to handle an effectively unbounded corpus. The scale constraint changes, but the core result does not. Once the right documents are surfaced, full-context reasoning continues to beat workflows built around fragmented retrieval and orchestration.
5) Building the Best Architecture for Serious Legal Work
If you are evaluating systems for document-heavy legal or enterprise analysis, the critical question is not simply whether a system can retrieve a highly ranked text span. The harder operational questions are whether the system can:
- Reliably surface the right governing documents from a massive corpus.
- Reason over those documents with full-context understanding intact.
- Carry that verified evidence seamlessly into a fully grounded final answer without compression loss.
This evaluation shows that the RAG extension of FCR does exactly that. It moves beyond both standard RAG and multi-agent systems by keeping document-level reasoning intact at scale.