FCR Outperforms Frontier Models on AA-LCR
On AA-LCR, Artificial Analysis's long-context reasoning benchmark, Full Context Reasoning reached 87.0% accuracy, outperformed every reported frontier-model baseline, and went 7-for-7 on the reviewed legal slice with verified deterministic citations.
Artificial Analysis has become one of the most widely watched benchmark suites for comparing LLMs. The result we focus on here is AA-LCR, its long-context reasoning subset, because it tests something more demanding than retrieval from a large context window: whether a system can reason faithfully over the evidence inside it.
That distinction matters more now than it did even a year ago. In 2026, long context is no longer rare. Many frontier models offer context windows at or near 1 million tokens, and even open-weight models now routinely support the same range. For many reasoning tasks, the hard part is no longer getting documents into the prompt. It is preserving their logic once the model starts working through them.
For years, the main bottleneck was getting the right information into the prompt at all. That bottleneck is much weaker now. If the documents fit, the model can see them.
But AA-LCR shows the deeper problem: seeing the information is not the same thing as reasoning correctly over it. Even when the answer is somewhere in the context, the model can still compress too aggressively, drop conditions, blur distinctions, or settle on a plausible interpretation that is weaker than what the documents actually support.
This is where FCR stands out. The result matters for three reasons: it outperformed every reported frontier-model baseline, went 7-for-7 on the reviewed legal slice, and paired its answers with verified deterministic citations. In long-context settings, reasoning and verification have to happen together. FCR is built for exactly that, which is why it opens a clear and meaningful gap over direct frontier-model prompting.
FCR Outperformed Frontier Models
| System | Accuracy |
|---|---|
| FCR | 87.0% |
| GPT-5.5 (xhigh) | 74.3% |
| Gemini 3.1 Pro Preview | 72.7% |
| Claude Opus 4.7 (max) | 70.3% |
| Kimi K2.6 | 69.7% |
| DeepSeek V4Pro (Max) | 66.3% |
Frontier-model scores are the AA-LCR results reported by Artificial Analysis. FCR was run by us on the same benchmark.
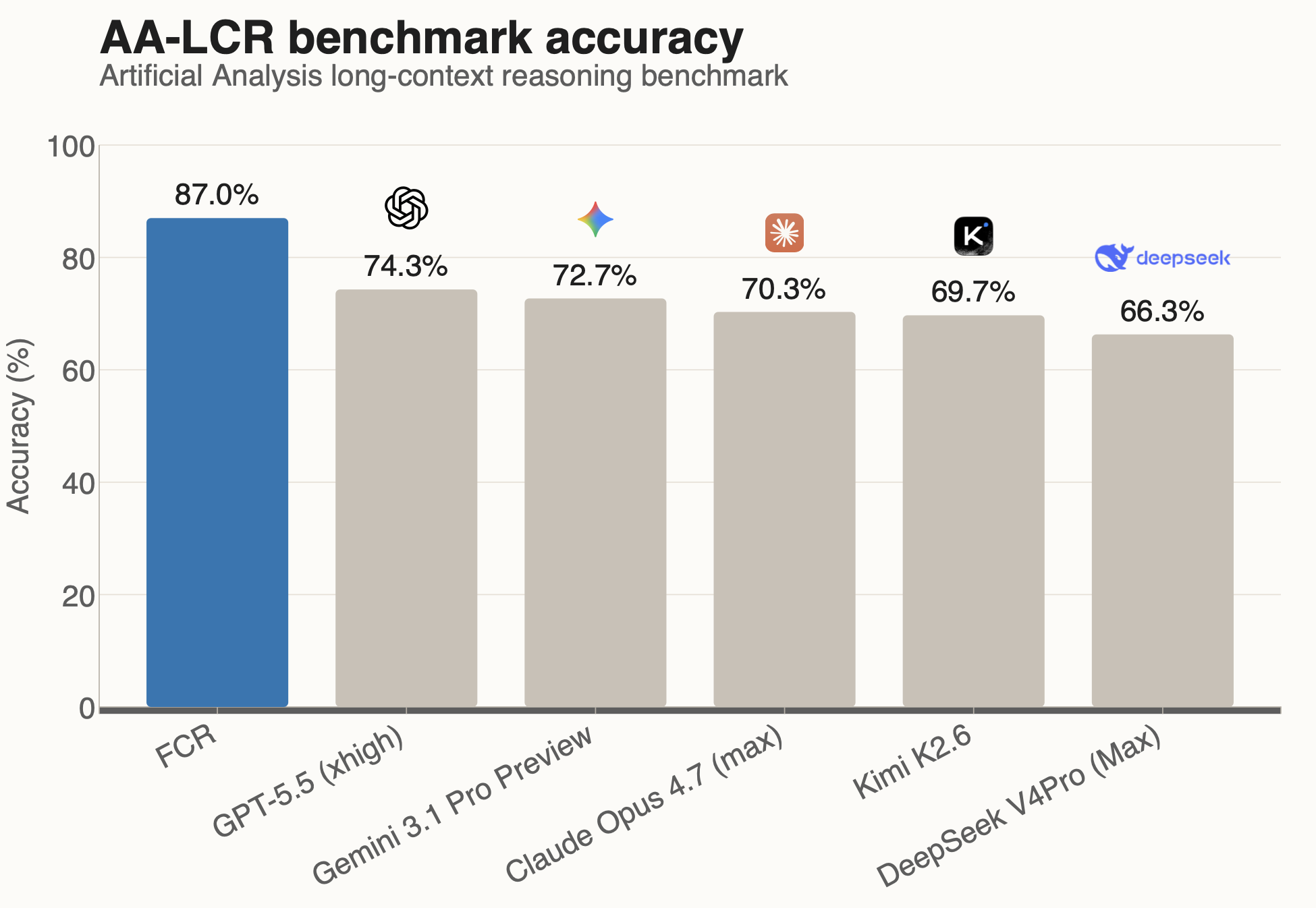
FCR finishes 12.7 points ahead of the best frontier baseline. This is not a marginal benchmark win. It is a decisive result, and it is the kind of gap you see when the underlying reasoning process is materially different.
Frontier models in this comparison are being asked to do something extremely difficult in one shot: read a large body of evidence, connect the right pieces, keep every qualification straight, and deliver an answer directly. On easier cases, that works. On harder ones, the model often makes a small mistake midway through the chain and never recovers. A weak intermediate step turns into a polished final answer, and because the output is fluent, the error is easy to miss.
FCR performs better because it does reasoning and verification together, not one after the other. The reasoning does not run loose and face scrutiny only at the end. It stays tied to the documents as it moves forward. That is the core advantage: FCR turns long context from a larger prompt into a more reliable reasoning process.
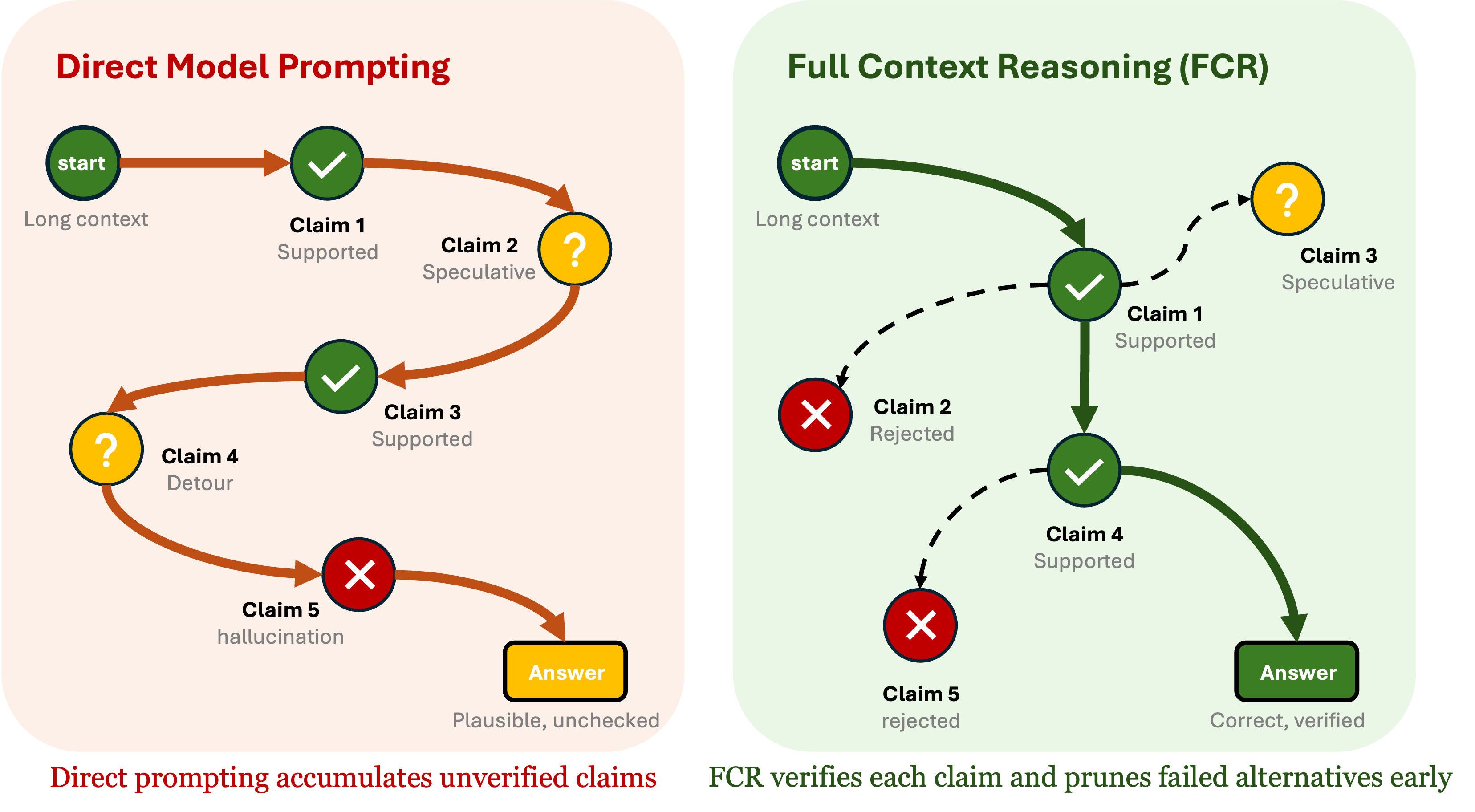
When the answer depends on several documents, the real risk is not usually total failure. The model often finds most of the right information. The problem is that it smooths over the part that actually matters: the exception, the narrower rule, the date tied to a specific provision, the qualifier that changes the meaning of the conclusion. Frontier models are strong at producing a coherent answer from a large prompt. FCR is stronger at making sure that coherence is earned.
That is why the gap shows up so clearly on AA-LCR. FCR is not winning because it writes prettier answers or hedges more. It is winning because it is less willing to let a plausible step become a trusted step before the documents support it. In long-context reasoning, that discipline is what separates answers that merely sound right from answers that are actually grounded.
FCR Went 7-for-7 on the Reviewed Legal Slice
Officially, AA-LCR labels 6 questions as Legal. In our review, we found one additional legal-style question that appears to have been misclassified outside that bucket, bringing the legal-style slice we reviewed to 7 questions in total.
Across those reviewed legal questions, FCR got 7/7 right when we checked the answers against the source documents. For legal work, that is exactly the kind of behavior that matters: not just finding relevant language, but preserving the legal force of the conditions, exceptions, and dates in that language.
That result is especially revealing because legal reasoning is not about producing the shortest or cleanest-looking answer. It is about preserving the exact legal condition, exception, or provision that the documents support.
One legal question asked whether the EU AI Act applies to public authorities outside the EU in a specific law-enforcement scenario. The benchmark gold answer flattened that into a simple "no." The documents did not support a flat no. They supported a conditional answer:
- under the general rule, the Act does apply when the output is used in the EU
- under a specific exception, it does not apply when the use falls under qualifying international law-enforcement agreements
That is a real legal distinction. If a model throws away the exception structure, it is not simplifying. It is getting the law wrong. FCR preserved the conditional structure instead of collapsing it.
In another legal case, FCR selected 2027 rather than the benchmark's 2026 because the question asked specifically about high-risk AI systems and the cited documents supported the more specific compliance date. Again, the point is not style. The point is that FCR tracked the more specific rule rather than defaulting to the broader, cleaner-looking one.
This is exactly where direct frontier-model prompting often looks strongest at first glance. The answer is fluent, concise, and confident. But if the documents support a conditional conclusion, or a more specific provision, and the output removes that distinction, the answer is worse even if it sounds cleaner. FCR's advantage is that it is built to keep those distinctions intact, which is why the legal result is more than a narrow slice score. It shows the kind of precision legal teams need from long-context AI.
Verified Deterministic Citations Matter
Performance is only part of the story. The other is whether the system can show exactly why an answer is correct.
FCR is built to produce verified deterministic citations. That means the system does not just give an answer that sounds right. It ties the answer back to specific source evidence in a way that is consistent, auditable, and grounded in the documents.
In high-stakes long-context work, a correct-looking answer is not enough. You need to know which document supports the conclusion, which passage carries the weight, and whether the reasoning still holds when you inspect the evidence directly.
This is also why FCR's legal performance matters. It is not just that it reached the right answer on the reviewed legal questions. It preserved the exact conditions, exceptions, and dates that the documents supported, and it did so with citations that can be checked.
What This Means
The takeaway is straightforward. Frontier models with long context are strong general-purpose readers. FCR is the stronger architecture when a task demands disciplined reasoning across long evidence.
FCR does not win by sounding smarter. It wins by being more faithful to the documents, more precise about conditions, and more reliable when the answer depends on getting the reasoning chain exactly right.
This is why the result matters. FCR is not just a better prompt. It is a better way to do long-context reasoning, with benchmark performance, legal precision, and verified deterministic citations built into the system.