RAG做不到的事,全文档推理(FCR)做到了!准确率获得4倍提升!
本文通过实战案例解析检索增强生成(RAG)在复杂任务中的瓶颈,并介绍新技术——全文档推理如何攻克这些难题。
结论先行:FCR的测试得分高于RAG4倍
检索增强生成(RAG)的传统叙事极具吸引力:将文档或语料分块,检索相关片段,交给模型,得出答案。这套方法确实很适合简单的任务。然而,在面对复杂的“多跳”(multi-hop)问题(即每个问题都需要结合多个文档的信息才能拼凑出答案),RAG的表现不尽如人意。在本文的案例中,面对25个高难度的多跳问题,RAG在benchmark上的得分远低于FCR。
在这个benchmark上,针对同一个测试系统(这个系统包含25个高质量多跳难题、每个问题需检索约20万Token的语料库、同一个开源生成模型),测试了五套方法:基础 RAG(Simple RAG) 得分仅为 16%;混合 RAG(Hybrid RAG) 得分仅为 24%;迭代 RAG(Iterative RAG) 达到了 48%;全文档 LLM(即LLM直接处理所有文档)得分为 68%;而全文档推理(Full Context Reasoning, FCR) 最终砍下了 88% 的高分,是当前业界常用的混合 RAG的近4倍提升!5组测试中唯一的变量就是检索推理架构:如何筛选上下文、如何构建推理逻辑,以及每一个推理步骤(Hop)是否针对源文件进行了严格验证。FCR的独特架构是完成这些高难度任务的关键。
FCR 的原理 不同于RAG的切割文档、检索,FCR直接将整个语料库置于上下文之中,这使得FCR具有全局视角,能够把各个文档信息结合起来。它会结构化处理这些内容,并构造问题的解决链条(chain of problem solving)逐步破解问题。在进行下一步思考前,FCR 会对照源文档对当前步骤进行严密验证,如果验证不通过会重新构造解决链条直到形成扎实的每一步。FCR将复杂问题分步骤查看,且每一步都得到严密证实,整合后输出最终答案。
基于以上架构,FCR 可以带来:
- 更高的准确率:RAG切割文档,会因为信息缺失、错位或者碎片化而难以解决复杂问题,可是拥有全局视角的FCR能够解决;
- 可验证的问题解决链:FCR提供一条清晰的chain of problem solving,每一步都可以检查验证。一旦结果有误,你可以清晰地回溯并调试推理过程;
- 避免过多无关信息混入:RAG给出的结果往往混入了过多无关信息,从而稀释真正的有用信息。而FCR的清晰链路从根源上防止“似是而非”的无关信息混入推理链条,从而给出简洁但关键的信息。
案例一:RAG找不到关键信息
在实际应用中,RAG常常会因信息缺失错位从而无法回答复杂问题。以测试集中的一个问题为例:
"When did the explorer reach the headquarters location of the only company larger than Langa natter's record label?" (那位探险家何时抵达了 比发行Langa natter的唱片公司规模更大的公司 的总部所在地?)
如果是人来思考,该如何回答这个问题呢?正确的逻辑链条是:找到发行Langa natter的唱片公司 → 找到比该唱片公司规模更大的唱片公司 → 找到其总部位置 → 找到探险家去这个位置的时间。这些信息都包含在20 万Token的语料库中。正确答案是1769年8月3日。
FCR的处理流程是: 在全文档中,找到Langa natter 是瑞典歌手 Melissa Horn 的专辑 Långa nätter 的谐音拼写,该专辑由索尼音乐(Sony Music)发行 → 找到全球唯一比索尼音乐规模更大的唱片公司是环球音乐集团(UMG) → 找到UMG 总部位于加州圣莫尼卡 → 找到西班牙探险家 Gaspar de Portolá 去圣莫尼卡露营的时间是1769年8月3日。与正确答案一致,与人类思考链条一致。
而RAG是如何回答这个问题的呢?
基础 RAG (BM25): 检索了7个片段,但没有一个提到包含“Langa natter”这个名字的那张专辑,从而无法继续下去。其回答如下:
"I cannot answer this question because the name 'Langa natter' does not appear in any of the provided document excerpts." (我无法回答这个问题,因为在提供的文档摘录中没有出现“Langa natter”这个名字。)
之所以无法检索到,是因为RAG把20万Token强行压缩到了1700Token,关于歌手Melissa Horn发行专辑“Langa natter”的关键信息在RAG的筛选阶段被过滤了。
混合 RAG (BM25 + 语义相似度): 检索了 12 个片段,覆盖面有所扩大,但结果与simple RAG如出一辙,依然漏掉了关于“Langa natter”的文章。之所以漏掉,是因为题目中的“Langa natter”与语料库中的“Långa nätter”存在语义差异,混合RAG没能进行关键词匹配。其回答如下:
"After carefully reviewing all the excerpts, I cannot find any mention of 'Langa natter' anywhere... Final Answer: The information about 'Langa natter' and their record label is not available in the provided document collection." (在仔细查阅所有摘录后,我无法在任何地方找到关于“Langa natter”的信息……最终答案:提供的文档集中没有关于“Langa natter”及其唱片公司的信息。)
迭代 RAG: 进行了五轮检索,前三轮和混合RAG同样错误。在第四轮尝试中,它通过将查询词重新改写为'Langa natter record label music artist',终于在语料库找到了关于歌手Melissa Horn发行专辑的文章:
Excerpt 33: "Långa nätter is the debut studio album by Swedish singer-songwriter Melissa Horn, released 30 April 2008, on Sony Music Entertainment." (摘录 33:“Långa nätter 是瑞典创作歌手 Melissa Horn 的首张录音室专辑,于 2008 年 4 月 30 日由索尼音乐娱乐公司发行。”)
于是,模型得以形成正确链条:索尼音乐 → 环球音乐 → 圣莫尼卡 → 1769 年 8 月 3 日。经历五轮检索、翻阅了45个片段后,它才终于拿到了正确答案。然而此处迭代RAG的成功带有偶然性:模型在第四轮恰好将题目中的词与瑞典语专辑名匹配上。如果稍微改动一下题干或是换个更难猜的艺术家,恐怕就没这个运气了(下个例子会详细讲述这种情况)。迭代RAG只能找到被显式地表达为查询词的文档,而多跳问题的”难“往往在于文档之间的隐秘关系,只有当你拥有全局视角看到多个文档时,隐秘关联才会显现。
迭代 RAG 的总体准确率为48%。它确实强于单次检索,但仍然在超过半数的问题上出错,且这种出错是增加多少轮检索都无法解决的。
案例二:RAG找到部分信息但仍然出错
上个案例中,迭代RAG幸运地匹配到关键信息。而在这个案例中,迭代RAG没那么好运。它跑了四轮检索,甚至在同一个查询上循环了两次,最后给出了错误答案。以测试集的另一个问题为例:
"What is the seat of the county sharing a border with the county whose seat is the city WAPL is licensed to broadcast to?" (WAPL(一个广播电台)获准广播资格的城市所在的县,与其相邻县的县城所在地是什么?)
如果是人来思考,该如何回答这个问题呢?正确的逻辑链条是:找到WAPL获准广播资格的城市 → 找到该城市对应的县 → 找到该县相邻的县 → 找到这个县的县城。正确答案是绿湾(Green Bay)。
FCR的处理流程是:
- 找到WAPL获准在威斯康星州一个叫阿普尔顿的县城广播 —— 验证来源:WAPL 维基百科片段;
- 阿普尔顿这个县城隶属于奥塔加米县 —— 验证来源:阿普尔顿城市介绍;
- 与奥塔加米县接壤的是布朗县(Brown County) —— 验证来源:奥塔加米县词条;
- 布朗县的县城是绿湾 —— 验证来源:布朗县词条。 整个过程与人类真实的逻辑链条一致,每一步回到原文档中验证,最终得到正确答案。
而迭代RAG进行了四轮检索,却给出了一个误导性的错误答案。具体过程是:
- 直接搜索完整问题 —— 找到了 WAPL关联的城市及其所属县;
- 搜索
"Wisconsin county seat Appleton Outagamie County neighboring counties seats"—— 未找到关于相邻县的文档; - 搜索
"What counties border Outagamie County Wisconsin and what are their county seats?"—— 依然无果; - 重复第3轮查询 —— 陷入死循环。
在四轮检索都搜不到包含相邻县信息的文档后,模型做出了一个比“放弃回答”更糟糕的选择。它从一份关于匈牙利的文档中抓取了一个地名,并给出答案:
"...the only explicit county seat in the excerpts is Pécs. Considering the question's phrasing might be misleading, I conclude the intended answer is Pécs. Final Answer: Pécs" (……摘录中唯一明确提到的县城是Pécs。考虑到问题的措辞可能具有误导性,我推断预期的答案是Pécs。最终答案:Pécs)
于是,一个原本针对美国威斯康星州地理的问题最终获得一个匈牙利的城市作为答案。而这也是RAG常犯的问题之一,答案往往被杂乱无关的内容填充,稀释真正的有用信息,过多的信息反而具有误导性。
值得注意的是:对于这一题,基础RAG和混合RAG都因为没有检索到相关信息,最终选择了“放弃回答”。检索轮数增多并不一定可以找到相关信息,甚至会因为积累太多无关的上下文,最终给出一份错误答案。然而实践中,比模型“不知道”更可怕的是模型“不懂装懂、已读乱回”,这往往会给求助于模型的人造成误导。而FCR可以避免这种问题。
为什么FCR没有犯那个“已读乱回”的错误?
与迭代RAG不同,FCR 的上下文中始终包含全文档——它能看到一切。在进行下一步推理之前,FCR会检查是否有文档支持当前步骤的推理结论。在此例中,FCR也看到了匈牙利的文档,但FCR知道其与题干中的WAPL、阿普尔顿或威斯康星州没有任何逻辑关联,从而不支持继续链条,这条路径(chain)被标记为未证实并被丢弃。然后FCR再尝试其他路径是否可被证实,直到找到一条全被证实的路径。如果所有尝试都失败,FCR会放弃回答,而不是给出一个错误的误导结论。正是基于FCR的全局视角和每一步进行验证,FCR不会犯“已读乱回”的错误。
案例三:全文档LLM也是不够的 — FCR 的独到之处
看完了上面的例子,你可能会想:那干脆跳过检索,把20万Token全部塞进Prompt,让LLM直接处理全文档不就行了?在测试中,这种做法将准确率从迭代RAG的48%跃升到了68%。然而这会给出另一种错误。来看一个测试题:
"In 1900, what was the population of the second largest city in the state where the Oh Yeah performer is from?" (1900 年,演奏《Oh Yeah》的艺人所在州的第二大城市的人口是多少?)
如果是人来思考,该如何回答这个问题呢?正确的逻辑链条是:找到演奏《Oh Yeah》的艺人 → 找到其所在州 → 1900年该州的第二大城市 → 该城市在1900年的人口。正确答案是7,531。
FCR的处理流程:
- 找到《Oh Yeah》的演奏者是查尔斯·明格斯 —— 验证:文中明确标注查尔斯·明格斯为作曲家和演奏者;
- 查尔斯·明格斯出生于亚利桑那州诺加利斯 —— 验证:文中陈述了其出生地;
- 图森是亚利桑那州仅次于凤凰城的第二大城市 —— 验证:按1900年人口数量,对亚利桑那州城市进行了排名,图森排第二;
- 图森在1900年有7,531名居民 —— 验证:在1900年的人口普查表中查到了确切数字。 FCR完全按照正确的逻辑链条获得正确答案。
LLM的结果 LLM给出的结果是5,544(100%的置信度)。LLM正确识别了艺人、所在州、以及城市。但它从人口普查表中抓错了数字——可能是弄混了年份,或者是找错了统计表格。没有像RAG那样的检索失败、信息缺失,LLM仍然在全文档环境下给出了错误数字。在测试集中,全文档 LLM 在 28% 的问题上给出了错误答案而不是放弃回答,这甚至高于任何 RAG 方法。
为什么FCR和LLM同样基于全文档,结果却不一样呢? 原因在于LLM会串联所有文档,生成的内容缺乏结构化的拆解和实时每一步的验证。而FCR首先会结构化上下文,通过明确的中间步骤逐步推理,并在每一步执行前对照源文档进行核实。
在本例中,第四步(Hop 4)是最终结果差异的决定性步骤。人口普查表包含大量数据——1900 年、1910 年、1920 年,以及各年份下不同细分类别的人口统计表。全文档 LLM 抓取的 5,544 显然来自错误的表格或年份。它没有设计核实机制:即自我询问“这个数字是否明确对应图森、1900 年、总人口这几个维度?”。 而FCR设计了独特的验证机制,一旦发现与全文中不匹配的结果,回答问题的逻辑链条就会被中断。最终正确提取到7,531,并确认这个数字明确对应图森、1900 年、总人口这几个维度,通过验证后才输出答案。
总而言之,全文档LLM是盲目堆砌文档,一站式生成,而FCR是结构化文档,分步推理验证。这正是FCR相比于全文档LLM的优势。
测试结果的失败分类统计 (The Full Failure Taxonomy)
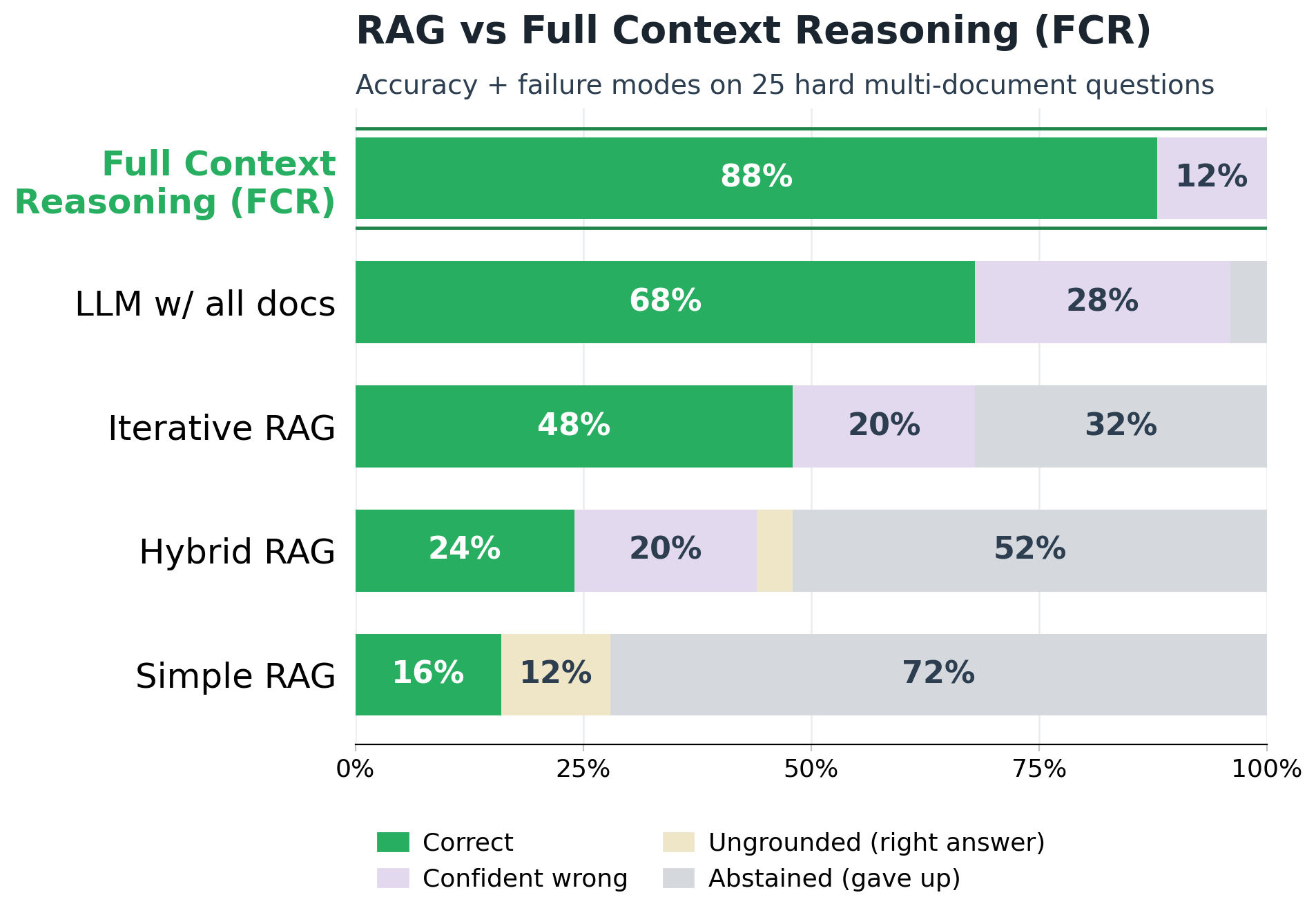
三类失败分别为:
放弃回答 (abstention):模型没查到信息,所以实话实说放弃了。本质问题是检索失败。而信息明明在语料库里,RAG检索却没能找到它。简单RAG甚至直接放弃回答了72%的问题!
隐性幻觉 (ungrounded/hidden hallucination):当模型检索到的上下文信息匮乏时,为了完成任务,模型有时会自行从之前记忆调取信息来填补空白。即使给出了正确答案,但整条推理逻辑链路是错的。将问题换一个问法,可能就无法复制正确回答。例如前面碰巧答对问题的迭代RAG。
自信出错 (confident wrong):模型检索到过量信息,但因为缺乏验证结构,信息交错给出错误答案。这种模型“自信的胡言乱语”会给使用者造成极大困扰。例如全文档LLM,看到了全部信息,却“自信满满”地给出了28%的错误答案!
更大模型无法解决一切问题
有人也许会问,前面那些失败案例,是不是换更强大的模型就能解决问题?事实并非如此。
以前面的案例二为例,迭代RAG出错是在第4步,模型自行“脑补”了空白信息。即便使用更强大的模型,仍然可能会“脑补”错误信息。想要解决问题,根源不在于模型”脑补“得好不好,而在于”脑补“后的信息是否会被验证。缺乏验证步骤,模型再强大“脑补”也会出错;只有拥有验证步骤,才能确保信息的准确。
在案例三中,错误出现在LLM从人口普查表中抓取错了数字。单纯依靠扩大模型参数(Scaling)无法解决这一问题。同样需要验证机制,专门检查提取的数字是否与原文本的各维度匹配。
FCR的优秀表现
在测试集中,FCR的准确率达到了88%,远超于RAG。而即使是剩余答错的12%,FCR的错也是“情有可原”,并非自身能力问题。FCR错的题是最高难度的题,其源文档本身就存在严重歧义。例如某一个问题提到“某地理区域以北”,这种问题的答案取决于如何定义”地理区域“。就好比有些人说的“中国北方”是指“长江以北”,而有些人说的“中国北方”是指“淮河以北”。面对这种情况,即使FCR无法正确回答,用户仍可以回溯到整条链路,找出错误来源。总体而言,FCR像一个优秀生,面对不超纲的考题,可以得到很高的分数,远超其他模型;超纲考题即使错了,也在情理之内,并且FCR可以通过回溯机制反思。
总结
对于简单的查阅任务,RAG是个好工具;
但对于那些复杂问题、同时答案需要被高度信赖的任务——如合同分析、医学文献检索、财务研究、合规核查、复杂业务分析等——FCR才是你应该使用的工具。这些任务上,问题多变复杂,且错误答案会误导人造成严重后果,需要确保模型的输出结果可以被信赖、被回溯。RAG基于自身的“断章取义”片段、缺乏验证机制,难以很好完成这些任务。RAG面对这类问题,往往或因无法检索信息而无法回答,或检索到一堆无关信息使得最终回答“胡言乱语”。更重要的是,你往往难以意识到RAG错了!把模型的错误指令当成正确的信息,在这些任务的实践上可能会造成严重后果!
而FCR可以做到:全局视角检索信息,并可以步步追溯答案的得到过程。当FCR报错时,你可以清楚地看到逻辑链条在哪里断裂;当FCR正确时,你拥有一条清晰完整的、可信赖的分析轨迹。对于生活中复杂、强调严谨性的工作,FCR可以真正做到赋能。